K nearest neighbour algorithm in data mining pdf
K nearest neighbour algorithm in data mining pdf
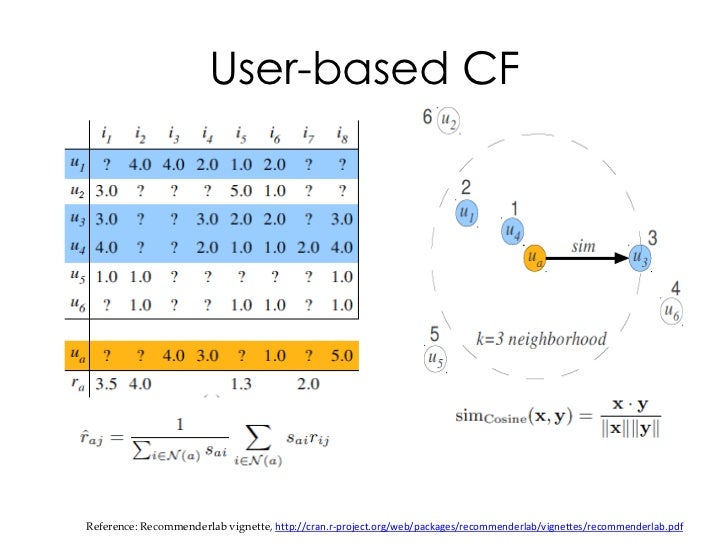
pattern recognition, information retrieval, machine learning, and data mining. Cluster analysis is Cluster analysis is a challenging task and there are a number of well …
Select a cell on the Data_Partition worksheet, then on the XLMiner ribbon, from the Data Mining tab, select Classify – k-Nearest Neighbors Classification to open the k-Nearest Neighbors Classification – Step 1 of 3 dialog.
Integrating k nearest neighbour single Inlier Outlier Range Random Row Random Attribute with k-means clustering could enhance k nearest neighbour accuracy in the diagnosis of heart disease FIGURE 5: INTEGRATING CLUSTERING WITH K NEAREST patients. The best results for the k nearest neighbour NEIGHBOUR is achieved by the two clusters inlier initial centroid selection …
k nearest neighbor (kNN) is an effective and powerful lazy learning algorithm, notwithstanding its easy-to-implement. However, its performance heavily relies on the quality of training data.
We’ll define K Nearest Neighbor algorithm for text classification with Python. KNN algorithm is used to classify by finding the K nearest matches in training data and then using the …
K-Nearest Neighbor Data Distributions. We run experiments on a variety of data stream We run experiments on a variety of data stream topologies and thereby demonstrate the effectiveness of the new algorithm in detecting outliers
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection. It is widely disposable in real-life scenarios since it is
What is k-Nearest Neighbors. The model for kNN is the entire training dataset. When a prediction is required for a unseen data instance, the kNN algorithm will search through the training dataset for the k-most similar instances.
easy data mining. k-Nearest Neighbour (kNN) they used bioinformatics resources extensively, although they The k-nearest neighbours algorithm is one of the simplest machine learning algorithms. It is simply based on the idea that “objects that are ‘near’ each other will also have similar characteristics. Thus if you know the characteristic features of one of the objects, you can also
The K-Nearest Neighbor (K-NN) algorithm is one of the simplest methods for solving classification problems; it often yields competitive results and has significant advantages over several other data mining methods. Our work is therefore based on the need to establish a flexible, transparent, consistent straightforward, simple to understand and easy to implement approach. This is achieved
People in data mining never test with the data they used to train the system. You can see why we don’t use the training data for testing if we consider the nearest neighbor algorithm.
Here, the k-Nearest Neighbor Algorithm Pseudo Code is framed using a function kNN() which takes a single test sample or instance, x as argument and returns a 2-D Vector containing the prediction result as the 1st element and the value of k as the 2nd element.
The “K” is KNN algorithm is the nearest neighbors we wish to take vote from. Let’s say K = 3. Hence, we will now make a circle with BS as center just as big as to enclose only three datapoints on the plane. Refer to following diagram for more details:
Nearest neighbor is a special case of k-nearest neighbor class. Where k value is 1 (k = 1). In this case, new data point target class will be assigned to the 1 Where k value is 1 (k = 1). In this case, new data point target class will be assigned to the 1 st closest neighbor.
A k-nearest-neighbor algorithm, often abbreviated k-nn, is an approach to data classification that estimates how likely a data point is to be a member of one group or the other depending on what group the data points nearest to it are in.
K-Nearest Neighbours GeeksforGeeks

k-Nearest Neighbors Classification Method Example solver
k-Nearest Neighbor Algorithm for Classification K. Ming Leung Abstract: An instance based learning method called the K-Nearest Neighbor or K-NN algorithm has been used in many applications in areas such as data mining, statistical pattern recognition, image processing. Suc-cessful applications include recognition of handwriting, satellite image and EKG pattern. Directory • Table of Contents
algorithm to improve the classification accuracy of drug data Classification of Heart Disease Using K- Nearest set or medicine. We used to genetic search as better result Neighbor and Genetic Algorithm…
Find the K nearest neighbors in the training data set based on the Euclidean distance Predict the class value by finding the maximum class represented in the K nearest neighbors Calculate the accuracy as n Accuracy = (# of correctly classified examples / # of testing examples) X 100. Example of Backward Elimination ¨ # training examples 100 ¨ # testing examples 100 ¨ # attributes 50 ¨ K 3
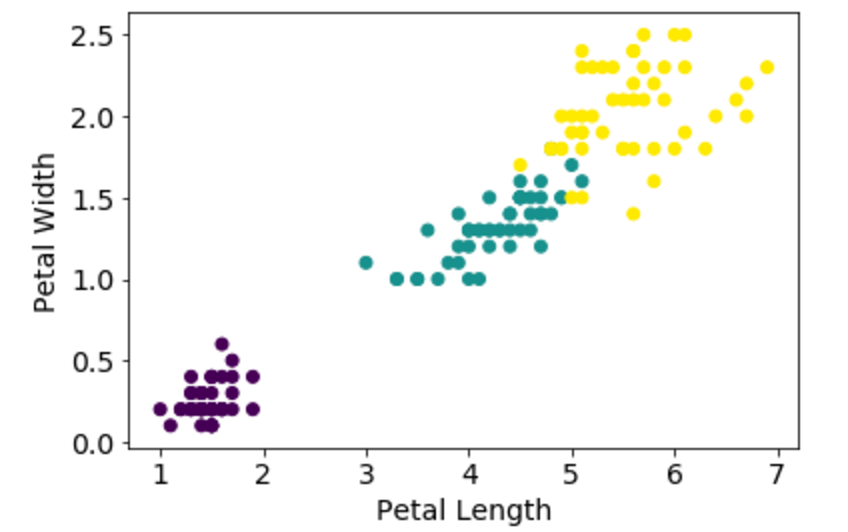
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
A data mining approach for fall detection by using k-nearest neighbor algorithm on wireless sensor network data Article in IET Communications 6(18):3281-3287 · December 2012 with 62 Reads
Nearest Neighbor Algorithm Store all of the training examples Classify a new example x by finding the training example hx i, y ii that is nearest to x according to
Data mining can be used to turn seemingly meaningless data into useful information, with rules, trends, and inferences that can be used to improve your business and revenue. This article will go over the last common data mining technique, ‘Nearest Neighbor,’ and will show you how to use the WEKA Java library in your server-side code to
in the diagnosis of heart disease. K-Nearest-Neighbour(KNN) is one of the successful data mining techniques used in classification problems. However, it is less used in the diagnosis of heart disease patients. Recently, researchers are showing that combining different classifiers through voting is outperforming other single classifiers. This paper investigates applying KNN to help healthcare
Data mining is the process of extracting the data from huge high dimensional databases, used as technology to produce the required information. The tendency of high-dimensional data enclose points hubs as shown in [1] that frequently occur in k-nearest neighbor lists of other points. Hubness successfully subjugated in clustering within a high-dimensional data cluster. Hub objects have minute

Nearest neighbor search Edo Liberty Algorithms in Data mining 1 Introduction The problem most commonly known as nearest neighbor search” is a fundamen-
K-Nearest Neighbor. Definition K-Nearest neighbor is a classification strategy that is an example of a “lazy learner.” Unlike all the other classification algorithms outlined on this site which are labeled “eager learners” “lazy learners” do not require building a model with a training set before actual use.
A Review of Data Classification Using K-Nearest Neighbour Algorithm Aman Kataria1, M. D. Singh2 1P.G. Scholar, Thapar University, Cover and Hart proposed an algorithm the K-Nearest Neighbor, which was finalized after some time. K-Nearest Neighbor can be calculated by calculating Euclidian distance, although other measures are also available but through Euclidian distance we have splendid
Machine learning explores the study and construction of algorithms that can learn from and make predictions on data. Such algorithms operate by building a model from an example training set of input observations in order to make data-driven predictions or decisions expressed as outputs, rather than following strictly static program instructions.
In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the k …
prediction. k-Nearest neighbor is an example of instance-based learning, in which the training data set is stored, so that a classification for a new unclassified record may be found simply by comparing it to the most similar records in the training set.
Application of k- Nearest Neighbour Classif ication in Medical Data Mining Hassan Shee Khamis, Kipruto W. Cheruiyot, Steph en Kimani Jomo Kenyatta University of Technology – ICSIT, Nairobi, Kenya.
The K-Nearest Neighbour algorithm is similar to the Nearest Neighbour algorithm, except that it looks at the closest K instances to the unclassified instance. The class of the new instance is then given by the class with the highest frequency of those K instances.
Data mining techniques have been widely used to mine knowledgeable information from medical data bases. In data mining classification is a supervised learning that can be used to design models describing important data classes, where class attribute is involved in the construction of the classifier. Nearest neighbor (KNN) is very simple, most popular, highly efficient and effective algorithm
A Review of classification in Web Usage Mining using K- Nearest Neighbour 1407 patterns, through the mining of log files and associated data from a particular web site.
Text Classification using K Nearest Neighbors – Towards
k NN Algorithm • 1 NN • Predict the same value/class as the nearest instance in the training set • k NN • find the k closest training points (small kxi −x0k according
k-Nearest Neighbour, binary neural network, discretisation, binning, quantisation I. INTRODUCTION Standard k-Nearest Neighbour (k-NN) is a widely applicable data mining algorithm that
Many data mining techniques like k-Nearest Neighbour (kNN), Association Rule Mining etc., have been applied to intrusion detection. This paper aims at application of kNN to a subset of records from the KDD Cup 1999 dataset for classification of connection records into normal or attacked data. The paper also applies kNN to the subset of records with the selected features proposed by Kok-Chin
This chapter introduces the k-Nearest Neighbors (kNN) algorithm for classification. kNN, originally proposed by Fix and Hodges [1] is a very simple ‘instance-based’ learning algorithm. Despite its simplicity, it can offer very good performance on some problems. We present a high level overview of
K-Nearest Neighbors, or KNN, is a family of simple: classification. and regression algorithms . based on Similarity (Distance) calculation between instances. Nearest Neighbor implements rote learning. It’s based on a local average calculation. It’s a smoother algorithm. Some experts have written that k-nearest neighbours do the best about one third of the time. It’s so simple that, in the game
K-nearest neighbour algorithm (KNN) is a classification method based on closest training samples. It It is an instance-based learning algorithms that, instead of …
neighbour as an imputation method for treating missing values; Section 6 describes how the Machine Learning algorithms C4.5 and CN2 treat missing data internally; Section 7 performs a comparative study of the k -nearest neighbour algorithm as an imputation – minecraft neighborhood house tutorial 54 Responses to K-Nearest Neighbors for Machine Learning Roberto July 23, 2016 at 4:37 am # KNN is good to looking for nearest date in two sets of data, excluding the nearest neighbor used? if not, what algorithm you should suggest me to solve the issue.
To summarize, in a k-nearest neighbor method, the outcome Y of the query point X is taken to be the average of the outcomes of its k-nearest neighbors. Technical Details STATISTICA k-Nearest Neighbors (KNN) is a memory-based model defined by a set of objects known as examples (also known as instances) for which the outcome are known (i.e., the examples are labeled).
In this paper we implemented the Fuzzy K-Nearest Neighbor method using the MapReduce paradigm to process on big data. Results on different data sets show that the proposed Fuzzy K-Nearest Neighbor method outperforms a better performance than the method reviewed in the literature.
The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security. The author investigates k‐nearest neighbor algorithm, which is most often used for classification task, although it can
The K-Nearest Neighbor algorithm was used alongside with five other classification methods to combine mining of web server logs and web contents for classifying users’ navigation
classification algorithms in data mining. It is based on homogeneity, which is drawing a comparison between the K Nearest Neighbor classification provide us with the decision outline locally which was developed due to the need to carry out discriminate analysis when reliable parametric estimates of probability densities are unknown or hard to define. K is a constant pre-defined by the user
Teknik K-Nearest Neighbor dengan melakukan langkah-langkah yaitu (Santoso, 2007), mulai input: Data training, label data traning, k, data testing a. Untuk semua data testing, hitung jaraknya ke setiap data training b. Tentukan k data training yang jaraknya paling dekat dengan data c. Testing d. Periksa label dari k data ini e. Tentukan label yang frekuensinya paling banyak f. Masukan data
Definition of K-Nearest Neighbor Classification: Is a data mining algorithm that is used to classify a given set of data into pre-defined classes. This algorithm is an example of supervised learning. This algorithm is an example of supervised learning.
Data mining creates Support Vector Machines (SVM), Artificial Neural classification models by examining already classified Networks (ANN), Naïve Bayesian Classifier, Genetic data (cases) and inductively finding a predictive Algorithm, and K-Nearest Neighbor (KNN). pattern. These existing cases may come from a This paper aims to investigate KNN method in classification and regression, …
The KNN or k-nearest neighbors algorithm is one of the simplest machine learning algorithms and is an example of instance-based learning, where new data are classified based on …
29/12/2017 · k nearest neighbour algorithm in data mining belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection
k-Nearest Neighbor (kNN) data mining algorithm in plain
also a number of more technical books about data mining algorithms, but these are aimed at the statistical researcher, or more advanced graduate student, and do not provide the case-oriented business focus that is successful in teaching business students.
k-nearest neighbor algorithm Summary The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security.
Outline The Classi cation Problem The k Nearest Neighbours Algorithm Condensed Nearest Neighbour Data Reduction Introduction to kNN Classi cation and CNN Data Reduction Oliver Sutton February, 2012 1/29. Outline The Classi cation Problem The k Nearest Neighbours Algorithm Condensed Nearest Neighbour Data Reduction 1 The Classi cation Problem Examples The Problem 2 The k Nearest …
This chapter focuses on an important machine learning algorithm called k-Nearest Neighbors (kNN), where k is an integer greater than 0. The kNN classification problem is to find the k nearest data points in a data set to a given query data point.
A data mining approach for fall detection by using k

k‐Nearest Neighbor Algorithm Discovering Knowledge in
ORIGINS OF K-NN • Nearest Neighbors have been used in statistical estimation and pattern recognition already in the beginning of 1970’s (non- parametric techniques). • The method prevailed in several disciplines and still it is one of the top 10 Data Mining algorithm.
Abstract— Classification is a data mining (machine learning) technique used to predict group membership for data instances. In this paper, we present the basic classification techniques. Several major kinds of classification method including decision tree induction, Bayesian networks, k-nearest neighbor classifier, case-based reasoning, genetic algorithm and fuzzy logic techniques. The goal
The kNN data mining algorithm is part of a longer article about many more data mining algorithms. What does it do? kNN, or k-Nearest Neighbors, is a classification algorithm.
The k-nearest neighbor ( k-NN) method is one of the data mining techniques considered to be among the top 10 techniques for data mining [237]. The k-NN method uses the well-known principle of Cicero
The k-Nearest Neighbor algorithm (k-NN) [2] is considered one of the ten most influential data mining algorithms [3]. It belongs to the lazy learning family of methods that do not need of an explicit training phase. This method requires that all of the data instances are stored and unseen cases classified by finding the class labels of the kclosest instances to them. To determine how close
K Nearest Neighbors Classification – Data Mining Map

CLUSTERING WITH SHARED NEAREST NEIGHBOR-UNSCENTED
K Nearest Neighbour Algorithm Data Mining

Application of k-Nearest Neighbour Classification Method
MODEL ALGORITMA K-NEAREST NEIGHBOR (K-NN) PDF Free
neil gaiman poem instructions – K-Nearest Neighbor (K-NN) Techopedia.com
Data Mining Algorithms In R/Classification/kNN Wikibooks

A New Shared Nearest Neighbor Clustering Algorithm and its
KNN SlideShare
A New Shared Nearest Neighbor Clustering Algorithm and its
A Review of Data Classification Using K-Nearest Neighbour
k-nearest neighbor algorithm Summary The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security.
This chapter introduces the k-Nearest Neighbors (kNN) algorithm for classification. kNN, originally proposed by Fix and Hodges [1] is a very simple ‘instance-based’ learning algorithm. Despite its simplicity, it can offer very good performance on some problems. We present a high level overview of
To summarize, in a k-nearest neighbor method, the outcome Y of the query point X is taken to be the average of the outcomes of its k-nearest neighbors. Technical Details STATISTICA k-Nearest Neighbors (KNN) is a memory-based model defined by a set of objects known as examples (also known as instances) for which the outcome are known (i.e., the examples are labeled).
K-Nearest Neighbor. Definition K-Nearest neighbor is a classification strategy that is an example of a “lazy learner.” Unlike all the other classification algorithms outlined on this site which are labeled “eager learners” “lazy learners” do not require building a model with a training set before actual use.
Data mining techniques have been widely used to mine knowledgeable information from medical data bases. In data mining classification is a supervised learning that can be used to design models describing important data classes, where class attribute is involved in the construction of the classifier. Nearest neighbor (KNN) is very simple, most popular, highly efficient and effective algorithm
Nearest neighbor search Edo Liberty Algorithms in Data mining 1 Introduction The problem most commonly known as nearest neighbor search” is a fundamen-
Learning Algorithm Oregon State University
A Review of Data Classification Using K-Nearest Neighbour
Here, the k-Nearest Neighbor Algorithm Pseudo Code is framed using a function kNN() which takes a single test sample or instance, x as argument and returns a 2-D Vector containing the prediction result as the 1st element and the value of k as the 2nd element.
The KNN or k-nearest neighbors algorithm is one of the simplest machine learning algorithms and is an example of instance-based learning, where new data are classified based on …
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection. It is widely disposable in real-life scenarios since it is
pattern recognition, information retrieval, machine learning, and data mining. Cluster analysis is Cluster analysis is a challenging task and there are a number of well …
easy data mining. k-Nearest Neighbour (kNN) they used bioinformatics resources extensively, although they The k-nearest neighbours algorithm is one of the simplest machine learning algorithms. It is simply based on the idea that “objects that are ‘near’ each other will also have similar characteristics. Thus if you know the characteristic features of one of the objects, you can also
k-Nearest Neighbour, binary neural network, discretisation, binning, quantisation I. INTRODUCTION Standard k-Nearest Neighbour (k-NN) is a widely applicable data mining algorithm that
We’ll define K Nearest Neighbor algorithm for text classification with Python. KNN algorithm is used to classify by finding the K nearest matches in training data and then using the …
Automated web usage data mining and recommendation system
A Review of Data Classification Using K-Nearest Neighbour
The K-Nearest Neighbor algorithm was used alongside with five other classification methods to combine mining of web server logs and web contents for classifying users’ navigation
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection. It is widely disposable in real-life scenarios since it is
A k-nearest-neighbor algorithm, often abbreviated k-nn, is an approach to data classification that estimates how likely a data point is to be a member of one group or the other depending on what group the data points nearest to it are in.
Machine learning explores the study and construction of algorithms that can learn from and make predictions on data. Such algorithms operate by building a model from an example training set of input observations in order to make data-driven predictions or decisions expressed as outputs, rather than following strictly static program instructions.
Outline The Classi cation Problem The k Nearest Neighbours Algorithm Condensed Nearest Neighbour Data Reduction Introduction to kNN Classi cation and CNN Data Reduction Oliver Sutton February, 2012 1/29. Outline The Classi cation Problem The k Nearest Neighbours Algorithm Condensed Nearest Neighbour Data Reduction 1 The Classi cation Problem Examples The Problem 2 The k Nearest …
Nearest Neighbor Algorithm Store all of the training examples Classify a new example x by finding the training example hx i, y ii that is nearest to x according to
Data mining techniques have been widely used to mine knowledgeable information from medical data bases. In data mining classification is a supervised learning that can be used to design models describing important data classes, where class attribute is involved in the construction of the classifier. Nearest neighbor (KNN) is very simple, most popular, highly efficient and effective algorithm
K-Nearest Neighbors, or KNN, is a family of simple: classification. and regression algorithms . based on Similarity (Distance) calculation between instances. Nearest Neighbor implements rote learning. It’s based on a local average calculation. It’s a smoother algorithm. Some experts have written that k-nearest neighbours do the best about one third of the time. It’s so simple that, in the game
Find the K nearest neighbors in the training data set based on the Euclidean distance Predict the class value by finding the maximum class represented in the K nearest neighbors Calculate the accuracy as n Accuracy = (# of correctly classified examples / # of testing examples) X 100. Example of Backward Elimination ¨ # training examples 100 ¨ # testing examples 100 ¨ # attributes 50 ¨ K 3
Here, the k-Nearest Neighbor Algorithm Pseudo Code is framed using a function kNN() which takes a single test sample or instance, x as argument and returns a 2-D Vector containing the prediction result as the 1st element and the value of k as the 2nd element.
The KNN or k-nearest neighbors algorithm is one of the simplest machine learning algorithms and is an example of instance-based learning, where new data are classified based on …
classification algorithms in data mining. It is based on homogeneity, which is drawing a comparison between the K Nearest Neighbor classification provide us with the decision outline locally which was developed due to the need to carry out discriminate analysis when reliable parametric estimates of probability densities are unknown or hard to define. K is a constant pre-defined by the user
k-Nearest Neighbor Algorithm for Classification K. Ming Leung Abstract: An instance based learning method called the K-Nearest Neighbor or K-NN algorithm has been used in many applications in areas such as data mining, statistical pattern recognition, image processing. Suc-cessful applications include recognition of handwriting, satellite image and EKG pattern. Directory • Table of Contents
In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the k …
Machine Learning K-Nearest Neighbors (KNN) algorithm
A Study of K-Nearest Neighbour as an Imputation Method
The K-Nearest Neighbor (K-NN) algorithm is one of the simplest methods for solving classification problems; it often yields competitive results and has significant advantages over several other data mining methods. Our work is therefore based on the need to establish a flexible, transparent, consistent straightforward, simple to understand and easy to implement approach. This is achieved
A k-nearest-neighbor algorithm, often abbreviated k-nn, is an approach to data classification that estimates how likely a data point is to be a member of one group or the other depending on what group the data points nearest to it are in.
29/12/2017 · k nearest neighbour algorithm in data mining belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection
Nearest Neighbor Algorithm Store all of the training examples Classify a new example x by finding the training example hx i, y ii that is nearest to x according to
k-Nearest Neighbor Algorithm for Classification K. Ming Leung Abstract: An instance based learning method called the K-Nearest Neighbor or K-NN algorithm has been used in many applications in areas such as data mining, statistical pattern recognition, image processing. Suc-cessful applications include recognition of handwriting, satellite image and EKG pattern. Directory • Table of Contents
easy data mining. k-Nearest Neighbour (kNN) they used bioinformatics resources extensively, although they The k-nearest neighbours algorithm is one of the simplest machine learning algorithms. It is simply based on the idea that “objects that are ‘near’ each other will also have similar characteristics. Thus if you know the characteristic features of one of the objects, you can also
What is k-Nearest Neighbors. The model for kNN is the entire training dataset. When a prediction is required for a unseen data instance, the kNN algorithm will search through the training dataset for the k-most similar instances.
K-Nearest Neighbor. Definition K-Nearest neighbor is a classification strategy that is an example of a “lazy learner.” Unlike all the other classification algorithms outlined on this site which are labeled “eager learners” “lazy learners” do not require building a model with a training set before actual use.
K-Nearest Neighbours GeeksforGeeks
A Review of classification in Web Usage Mining using K
A data mining approach for fall detection by using k-nearest neighbor algorithm on wireless sensor network data Article in IET Communications 6(18):3281-3287 · December 2012 with 62 Reads
Integrating k nearest neighbour single Inlier Outlier Range Random Row Random Attribute with k-means clustering could enhance k nearest neighbour accuracy in the diagnosis of heart disease FIGURE 5: INTEGRATING CLUSTERING WITH K NEAREST patients. The best results for the k nearest neighbour NEIGHBOUR is achieved by the two clusters inlier initial centroid selection …
The k-Nearest Neighbor algorithm (k-NN) [2] is considered one of the ten most influential data mining algorithms [3]. It belongs to the lazy learning family of methods that do not need of an explicit training phase. This method requires that all of the data instances are stored and unseen cases classified by finding the class labels of the kclosest instances to them. To determine how close
ORIGINS OF K-NN • Nearest Neighbors have been used in statistical estimation and pattern recognition already in the beginning of 1970’s (non- parametric techniques). • The method prevailed in several disciplines and still it is one of the top 10 Data Mining algorithm.
Select a cell on the Data_Partition worksheet, then on the XLMiner ribbon, from the Data Mining tab, select Classify – k-Nearest Neighbors Classification to open the k-Nearest Neighbors Classification – Step 1 of 3 dialog.
also a number of more technical books about data mining algorithms, but these are aimed at the statistical researcher, or more advanced graduate student, and do not provide the case-oriented business focus that is successful in teaching business students.
The K-Nearest Neighbor algorithm was used alongside with five other classification methods to combine mining of web server logs and web contents for classifying users’ navigation
The k-nearest neighbor ( k-NN) method is one of the data mining techniques considered to be among the top 10 techniques for data mining [237]. The k-NN method uses the well-known principle of Cicero
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection. It is widely disposable in real-life scenarios since it is
Journal of Technology Application of k- Nearest Neighbour
Nearest neighbor search GitHub Pages
Teknik K-Nearest Neighbor dengan melakukan langkah-langkah yaitu (Santoso, 2007), mulai input: Data training, label data traning, k, data testing a. Untuk semua data testing, hitung jaraknya ke setiap data training b. Tentukan k data training yang jaraknya paling dekat dengan data c. Testing d. Periksa label dari k data ini e. Tentukan label yang frekuensinya paling banyak f. Masukan data
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
Outline The Classi cation Problem The k Nearest Neighbours Algorithm Condensed Nearest Neighbour Data Reduction Introduction to kNN Classi cation and CNN Data Reduction Oliver Sutton February, 2012 1/29. Outline The Classi cation Problem The k Nearest Neighbours Algorithm Condensed Nearest Neighbour Data Reduction 1 The Classi cation Problem Examples The Problem 2 The k Nearest …
The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security. The author investigates k‐nearest neighbor algorithm, which is most often used for classification task, although it can
ORIGINS OF K-NN • Nearest Neighbors have been used in statistical estimation and pattern recognition already in the beginning of 1970’s (non- parametric techniques). • The method prevailed in several disciplines and still it is one of the top 10 Data Mining algorithm.
The K-Nearest Neighbour algorithm is similar to the Nearest Neighbour algorithm, except that it looks at the closest K instances to the unclassified instance. The class of the new instance is then given by the class with the highest frequency of those K instances.
We’ll define K Nearest Neighbor algorithm for text classification with Python. KNN algorithm is used to classify by finding the K nearest matches in training data and then using the …
Nearest Neighbor Algorithm Store all of the training examples Classify a new example x by finding the training example hx i, y ii that is nearest to x according to
Find the K nearest neighbors in the training data set based on the Euclidean distance Predict the class value by finding the maximum class represented in the K nearest neighbors Calculate the accuracy as n Accuracy = (# of correctly classified examples / # of testing examples) X 100. Example of Backward Elimination ¨ # training examples 100 ¨ # testing examples 100 ¨ # attributes 50 ¨ K 3
The K-Nearest Neighbor (K-NN) algorithm is one of the simplest methods for solving classification problems; it often yields competitive results and has significant advantages over several other data mining methods. Our work is therefore based on the need to establish a flexible, transparent, consistent straightforward, simple to understand and easy to implement approach. This is achieved
In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the k …
A k-nearest-neighbor algorithm, often abbreviated k-nn, is an approach to data classification that estimates how likely a data point is to be a member of one group or the other depending on what group the data points nearest to it are in.
Nearest neighbor search Edo Liberty Algorithms in Data mining 1 Introduction The problem most commonly known as nearest neighbor search” is a fundamen-
The k-nearest neighbor ( k-NN) method is one of the data mining techniques considered to be among the top 10 techniques for data mining [237]. The k-NN method uses the well-known principle of Cicero
A New Shared Nearest Neighbor Clustering Algorithm and its
k-Nearest Neighbor Algorithm Discovering Knowledge in
algorithm to improve the classification accuracy of drug data Classification of Heart Disease Using K- Nearest set or medicine. We used to genetic search as better result Neighbor and Genetic Algorithm…
The k-Nearest Neighbor algorithm (k-NN) [2] is considered one of the ten most influential data mining algorithms [3]. It belongs to the lazy learning family of methods that do not need of an explicit training phase. This method requires that all of the data instances are stored and unseen cases classified by finding the class labels of the kclosest instances to them. To determine how close
K-nearest neighbour algorithm (KNN) is a classification method based on closest training samples. It It is an instance-based learning algorithms that, instead of …
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
k‐Nearest Neighbor Algorithm Discovering Knowledge in
k-Nearest Neighbor Classification SpringerLink
Data mining creates Support Vector Machines (SVM), Artificial Neural classification models by examining already classified Networks (ANN), Naïve Bayesian Classifier, Genetic data (cases) and inductively finding a predictive Algorithm, and K-Nearest Neighbor (KNN). pattern. These existing cases may come from a This paper aims to investigate KNN method in classification and regression, …
Definition of K-Nearest Neighbor Classification: Is a data mining algorithm that is used to classify a given set of data into pre-defined classes. This algorithm is an example of supervised learning. This algorithm is an example of supervised learning.
k-Nearest Neighbour, binary neural network, discretisation, binning, quantisation I. INTRODUCTION Standard k-Nearest Neighbour (k-NN) is a widely applicable data mining algorithm that
K-Nearest Neighbor Data Distributions. We run experiments on a variety of data stream We run experiments on a variety of data stream topologies and thereby demonstrate the effectiveness of the new algorithm in detecting outliers
prediction. k-Nearest neighbor is an example of instance-based learning, in which the training data set is stored, so that a classification for a new unclassified record may be found simply by comparing it to the most similar records in the training set.
easy data mining. k-Nearest Neighbour (kNN) they used bioinformatics resources extensively, although they The k-nearest neighbours algorithm is one of the simplest machine learning algorithms. It is simply based on the idea that “objects that are ‘near’ each other will also have similar characteristics. Thus if you know the characteristic features of one of the objects, you can also
What is k-Nearest Neighbors. The model for kNN is the entire training dataset. When a prediction is required for a unseen data instance, the kNN algorithm will search through the training dataset for the k-most similar instances.
This chapter introduces the k-Nearest Neighbors (kNN) algorithm for classification. kNN, originally proposed by Fix and Hodges [1] is a very simple ‘instance-based’ learning algorithm. Despite its simplicity, it can offer very good performance on some problems. We present a high level overview of
Data mining is the process of extracting the data from huge high dimensional databases, used as technology to produce the required information. The tendency of high-dimensional data enclose points hubs as shown in [1] that frequently occur in k-nearest neighbor lists of other points. Hubness successfully subjugated in clustering within a high-dimensional data cluster. Hub objects have minute
Integrating Clustering with Different Data Mining
Machine Learning K-Nearest Neighbors (KNN) algorithm
54 Responses to K-Nearest Neighbors for Machine Learning Roberto July 23, 2016 at 4:37 am # KNN is good to looking for nearest date in two sets of data, excluding the nearest neighbor used? if not, what algorithm you should suggest me to solve the issue.
The KNN or k-nearest neighbors algorithm is one of the simplest machine learning algorithms and is an example of instance-based learning, where new data are classified based on …
The K-Nearest Neighbor algorithm was used alongside with five other classification methods to combine mining of web server logs and web contents for classifying users’ navigation
To summarize, in a k-nearest neighbor method, the outcome Y of the query point X is taken to be the average of the outcomes of its k-nearest neighbors. Technical Details STATISTICA k-Nearest Neighbors (KNN) is a memory-based model defined by a set of objects known as examples (also known as instances) for which the outcome are known (i.e., the examples are labeled).
k NN Algorithm • 1 NN • Predict the same value/class as the nearest instance in the training set • k NN • find the k closest training points (small kxi −x0k according
Application of k- Nearest Neighbour Classif ication in Medical Data Mining Hassan Shee Khamis, Kipruto W. Cheruiyot, Steph en Kimani Jomo Kenyatta University of Technology – ICSIT, Nairobi, Kenya.
A Review of Data Classification Using K-Nearest Neighbour
A Review on Recommendation System and Web Usage Data
k NN Algorithm • 1 NN • Predict the same value/class as the nearest instance in the training set • k NN • find the k closest training points (small kxi −x0k according
prediction. k-Nearest neighbor is an example of instance-based learning, in which the training data set is stored, so that a classification for a new unclassified record may be found simply by comparing it to the most similar records in the training set.
The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security. The author investigates k‐nearest neighbor algorithm, which is most often used for classification task, although it can
The “K” is KNN algorithm is the nearest neighbors we wish to take vote from. Let’s say K = 3. Hence, we will now make a circle with BS as center just as big as to enclose only three datapoints on the plane. Refer to following diagram for more details:
also a number of more technical books about data mining algorithms, but these are aimed at the statistical researcher, or more advanced graduate student, and do not provide the case-oriented business focus that is successful in teaching business students.
29/12/2017 · k nearest neighbour algorithm in data mining belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection
Data mining with WEKA Part 3 Nearest Neighbor and IBM
Discretisation of Data in a Binary Neural k-Nearest
Data mining creates Support Vector Machines (SVM), Artificial Neural classification models by examining already classified Networks (ANN), Naïve Bayesian Classifier, Genetic data (cases) and inductively finding a predictive Algorithm, and K-Nearest Neighbor (KNN). pattern. These existing cases may come from a This paper aims to investigate KNN method in classification and regression, …
Nearest Neighbor Algorithm Store all of the training examples Classify a new example x by finding the training example hx i, y ii that is nearest to x according to
This chapter focuses on an important machine learning algorithm called k-Nearest Neighbors (kNN), where k is an integer greater than 0. The kNN classification problem is to find the k nearest data points in a data set to a given query data point.
The “K” is KNN algorithm is the nearest neighbors we wish to take vote from. Let’s say K = 3. Hence, we will now make a circle with BS as center just as big as to enclose only three datapoints on the plane. Refer to following diagram for more details:
Effective Outlier Detection using K-Nearest Neighbor Data
Application of k-Nearest Neighbour Classification Method
54 Responses to K-Nearest Neighbors for Machine Learning Roberto July 23, 2016 at 4:37 am # KNN is good to looking for nearest date in two sets of data, excluding the nearest neighbor used? if not, what algorithm you should suggest me to solve the issue.
This chapter focuses on an important machine learning algorithm called k-Nearest Neighbors (kNN), where k is an integer greater than 0. The kNN classification problem is to find the k nearest data points in a data set to a given query data point.
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
k-nearest neighbor algorithm Summary The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security.
K-Nearest Neighbor. Definition K-Nearest neighbor is a classification strategy that is an example of a “lazy learner.” Unlike all the other classification algorithms outlined on this site which are labeled “eager learners” “lazy learners” do not require building a model with a training set before actual use.
Nearest Neighbor Algorithm Store all of the training examples Classify a new example x by finding the training example hx i, y ii that is nearest to x according to
classification algorithms in data mining. It is based on homogeneity, which is drawing a comparison between the K Nearest Neighbor classification provide us with the decision outline locally which was developed due to the need to carry out discriminate analysis when reliable parametric estimates of probability densities are unknown or hard to define. K is a constant pre-defined by the user
A MapReduce-Based k-Nearest Neighbor Approach for Big Data
Text Classification using K Nearest Neighbors – Towards
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection. It is widely disposable in real-life scenarios since it is
in the diagnosis of heart disease. K-Nearest-Neighbour(KNN) is one of the successful data mining techniques used in classification problems. However, it is less used in the diagnosis of heart disease patients. Recently, researchers are showing that combining different classifiers through voting is outperforming other single classifiers. This paper investigates applying KNN to help healthcare
Many data mining techniques like k-Nearest Neighbour (kNN), Association Rule Mining etc., have been applied to intrusion detection. This paper aims at application of kNN to a subset of records from the KDD Cup 1999 dataset for classification of connection records into normal or attacked data. The paper also applies kNN to the subset of records with the selected features proposed by Kok-Chin
The K-Nearest Neighbour algorithm is similar to the Nearest Neighbour algorithm, except that it looks at the closest K instances to the unclassified instance. The class of the new instance is then given by the class with the highest frequency of those K instances.
Application of k- Nearest Neighbour Classif ication in Medical Data Mining Hassan Shee Khamis, Kipruto W. Cheruiyot, Steph en Kimani Jomo Kenyatta University of Technology – ICSIT, Nairobi, Kenya.
Machine learning explores the study and construction of algorithms that can learn from and make predictions on data. Such algorithms operate by building a model from an example training set of input observations in order to make data-driven predictions or decisions expressed as outputs, rather than following strictly static program instructions.
Find the K nearest neighbors in the training data set based on the Euclidean distance Predict the class value by finding the maximum class represented in the K nearest neighbors Calculate the accuracy as n Accuracy = (# of correctly classified examples / # of testing examples) X 100. Example of Backward Elimination ¨ # training examples 100 ¨ # testing examples 100 ¨ # attributes 50 ¨ K 3
Data mining can be used to turn seemingly meaningless data into useful information, with rules, trends, and inferences that can be used to improve your business and revenue. This article will go over the last common data mining technique, ‘Nearest Neighbor,’ and will show you how to use the WEKA Java library in your server-side code to
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
K-Nearest Neighbor Data Distributions. We run experiments on a variety of data stream We run experiments on a variety of data stream topologies and thereby demonstrate the effectiveness of the new algorithm in detecting outliers
classification algorithms in data mining. It is based on homogeneity, which is drawing a comparison between the K Nearest Neighbor classification provide us with the decision outline locally which was developed due to the need to carry out discriminate analysis when reliable parametric estimates of probability densities are unknown or hard to define. K is a constant pre-defined by the user
K-Nearest Neighbor Human-Oriented
K-Nearest Neighbor (K-NN) Techopedia.com
A Review of Data Classification Using K-Nearest Neighbour Algorithm Aman Kataria1, M. D. Singh2 1P.G. Scholar, Thapar University, Cover and Hart proposed an algorithm the K-Nearest Neighbor, which was finalized after some time. K-Nearest Neighbor can be calculated by calculating Euclidian distance, although other measures are also available but through Euclidian distance we have splendid
29/12/2017 · k nearest neighbour algorithm in data mining belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection
k nearest neighbor (kNN) is an effective and powerful lazy learning algorithm, notwithstanding its easy-to-implement. However, its performance heavily relies on the quality of training data.
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection. It is widely disposable in real-life scenarios since it is
K-Nearest Neighbours GeeksforGeeks
k-Nearest Neighbor Classification SpringerLink
To summarize, in a k-nearest neighbor method, the outcome Y of the query point X is taken to be the average of the outcomes of its k-nearest neighbors. Technical Details STATISTICA k-Nearest Neighbors (KNN) is a memory-based model defined by a set of objects known as examples (also known as instances) for which the outcome are known (i.e., the examples are labeled).
This chapter focuses on an important machine learning algorithm called k-Nearest Neighbors (kNN), where k is an integer greater than 0. The kNN classification problem is to find the k nearest data points in a data set to a given query data point.
k nearest neighbor (kNN) is an effective and powerful lazy learning algorithm, notwithstanding its easy-to-implement. However, its performance heavily relies on the quality of training data.
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection. It is widely disposable in real-life scenarios since it is
Here, the k-Nearest Neighbor Algorithm Pseudo Code is framed using a function kNN() which takes a single test sample or instance, x as argument and returns a 2-D Vector containing the prediction result as the 1st element and the value of k as the 2nd element.
Integrating Clustering with Different Data Mining
A Review of Data Classification Using K-Nearest Neighbour
pattern recognition, information retrieval, machine learning, and data mining. Cluster analysis is Cluster analysis is a challenging task and there are a number of well …
We’ll define K Nearest Neighbor algorithm for text classification with Python. KNN algorithm is used to classify by finding the K nearest matches in training data and then using the …
This chapter introduces the k-Nearest Neighbors (kNN) algorithm for classification. kNN, originally proposed by Fix and Hodges [1] is a very simple ‘instance-based’ learning algorithm. Despite its simplicity, it can offer very good performance on some problems. We present a high level overview of
In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the k …
The K-Nearest Neighbor algorithm was used alongside with five other classification methods to combine mining of web server logs and web contents for classifying users’ navigation
The K-Nearest Neighbor (K-NN) algorithm is one of the simplest methods for solving classification problems; it often yields competitive results and has significant advantages over several other data mining methods. Our work is therefore based on the need to establish a flexible, transparent, consistent straightforward, simple to understand and easy to implement approach. This is achieved
Nearest Neighbor Algorithm Store all of the training examples Classify a new example x by finding the training example hx i, y ii that is nearest to x according to
The k-Nearest Neighbor algorithm (k-NN) [2] is considered one of the ten most influential data mining algorithms [3]. It belongs to the lazy learning family of methods that do not need of an explicit training phase. This method requires that all of the data instances are stored and unseen cases classified by finding the class labels of the kclosest instances to them. To determine how close
A Review of Data Classification Using K-Nearest Neighbour Algorithm Aman Kataria1, M. D. Singh2 1P.G. Scholar, Thapar University, Cover and Hart proposed an algorithm the K-Nearest Neighbor, which was finalized after some time. K-Nearest Neighbor can be calculated by calculating Euclidian distance, although other measures are also available but through Euclidian distance we have splendid
Select a cell on the Data_Partition worksheet, then on the XLMiner ribbon, from the Data Mining tab, select Classify – k-Nearest Neighbors Classification to open the k-Nearest Neighbors Classification – Step 1 of 3 dialog.
People in data mining never test with the data they used to train the system. You can see why we don’t use the training data for testing if we consider the nearest neighbor algorithm.
Applying k-Nearest Neighbour in Diagnosing Heart Disease
K-Nearest Neighbours GeeksforGeeks
Find the K nearest neighbors in the training data set based on the Euclidean distance Predict the class value by finding the maximum class represented in the K nearest neighbors Calculate the accuracy as n Accuracy = (# of correctly classified examples / # of testing examples) X 100. Example of Backward Elimination ¨ # training examples 100 ¨ # testing examples 100 ¨ # attributes 50 ¨ K 3
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection. It is widely disposable in real-life scenarios since it is
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
k NN Algorithm • 1 NN • Predict the same value/class as the nearest instance in the training set • k NN • find the k closest training points (small kxi −x0k according
This chapter focuses on an important machine learning algorithm called k-Nearest Neighbors (kNN), where k is an integer greater than 0. The kNN classification problem is to find the k nearest data points in a data set to a given query data point.
In this paper we implemented the Fuzzy K-Nearest Neighbor method using the MapReduce paradigm to process on big data. Results on different data sets show that the proposed Fuzzy K-Nearest Neighbor method outperforms a better performance than the method reviewed in the literature.
The k-nearest neighbor ( k-NN) method is one of the data mining techniques considered to be among the top 10 techniques for data mining [237]. The k-NN method uses the well-known principle of Cicero
In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the k …
in the diagnosis of heart disease. K-Nearest-Neighbour(KNN) is one of the successful data mining techniques used in classification problems. However, it is less used in the diagnosis of heart disease patients. Recently, researchers are showing that combining different classifiers through voting is outperforming other single classifiers. This paper investigates applying KNN to help healthcare
algorithm to improve the classification accuracy of drug data Classification of Heart Disease Using K- Nearest set or medicine. We used to genetic search as better result Neighbor and Genetic Algorithm…
In this paper we implemented the Fuzzy K-Nearest Neighbor method using the MapReduce paradigm to process on big data. Results on different data sets show that the proposed Fuzzy K-Nearest Neighbor method outperforms a better performance than the method reviewed in the literature.
A Study of K-Nearest Neighbour as an Imputation Method
13. k-Nearest Neighbors Data Algorithms [Book]
classification algorithms in data mining. It is based on homogeneity, which is drawing a comparison between the K Nearest Neighbor classification provide us with the decision outline locally which was developed due to the need to carry out discriminate analysis when reliable parametric estimates of probability densities are unknown or hard to define. K is a constant pre-defined by the user
IRJET- Classification of Chemical Medicine or Drug using K
Application of k-Nearest Neighbour Classification Method
A Review on Recommendation System and Web Usage Data
What is k-Nearest Neighbors. The model for kNN is the entire training dataset. When a prediction is required for a unseen data instance, the kNN algorithm will search through the training dataset for the k-most similar instances.
Journal of Technology Application of k- Nearest Neighbour
Data Classification Algorithm Using k-Nearest Neighbour
The K-Nearest Neighbour algorithm is similar to the Nearest Neighbour algorithm, except that it looks at the closest K instances to the unclassified instance. The class of the new instance is then given by the class with the highest frequency of those K instances.
K-Nearest Neighbours GeeksforGeeks
54 Responses to K-Nearest Neighbors for Machine Learning Roberto July 23, 2016 at 4:37 am # KNN is good to looking for nearest date in two sets of data, excluding the nearest neighbor used? if not, what algorithm you should suggest me to solve the issue.
IRJET- Classification of Chemical Medicine or Drug using K
Integrating Clustering with Different Data Mining
k-Nearest Neighbor Classification SpringerLink
Nearest neighbor search Edo Liberty Algorithms in Data mining 1 Introduction The problem most commonly known as nearest neighbor search” is a fundamen-
KNN SlideShare
A Review on Recommendation System and Web Usage Data
K-Nearest Neighbor (K-NN) Techopedia.com
Select a cell on the Data_Partition worksheet, then on the XLMiner ribbon, from the Data Mining tab, select Classify – k-Nearest Neighbors Classification to open the k-Nearest Neighbors Classification – Step 1 of 3 dialog.
knn (k nearest neighbor) algorithm in data mining YouTube
A MapReduce-Based k-Nearest Neighbor Approach for Big Data
k-Nearest Neighbor (kNN) data mining algorithm in plain
K-nearest neighbour algorithm (KNN) is a classification method based on closest training samples. It It is an instance-based learning algorithms that, instead of …
k-Nearest Neighbor Algorithm Discovering Knowledge in
Integrating k nearest neighbour single Inlier Outlier Range Random Row Random Attribute with k-means clustering could enhance k nearest neighbour accuracy in the diagnosis of heart disease FIGURE 5: INTEGRATING CLUSTERING WITH K NEAREST patients. The best results for the k nearest neighbour NEIGHBOUR is achieved by the two clusters inlier initial centroid selection …
KNN SlideShare
CLUSTERING WITH SHARED NEAREST NEIGHBOR-UNSCENTED
Learning Algorithm Oregon State University
k-nearest neighbor algorithm Summary The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security.
Journal of Technology Application of k- Nearest Neighbour
knn (k nearest neighbor) algorithm in data mining YouTube
Discretisation of Data in a Binary Neural k-Nearest
pattern recognition, information retrieval, machine learning, and data mining. Cluster analysis is Cluster analysis is a challenging task and there are a number of well …
Application of k-Nearest Neighbour Classification Method
Discretisation of Data in a Binary Neural k-Nearest
A Review on Recommendation System and Web Usage Data
Data mining is the process of extracting the data from huge high dimensional databases, used as technology to produce the required information. The tendency of high-dimensional data enclose points hubs as shown in [1] that frequently occur in k-nearest neighbor lists of other points. Hubness successfully subjugated in clustering within a high-dimensional data cluster. Hub objects have minute
Text Classification using K Nearest Neighbors – Towards
13. k-Nearest Neighbors Data Algorithms [Book]
Effective Outlier Detection using K-Nearest Neighbor Data
Application of k- Nearest Neighbour Classif ication in Medical Data Mining Hassan Shee Khamis, Kipruto W. Cheruiyot, Steph en Kimani Jomo Kenyatta University of Technology – ICSIT, Nairobi, Kenya.
k-Nearest Neighbors Classification Method Example solver
Noisy data elimination using mutual k-nearest neighbor for
k-Nearest Neighbor Algorithm Discovering Knowledge in
The K-Nearest Neighbor (K-NN) algorithm is one of the simplest methods for solving classification problems; it often yields competitive results and has significant advantages over several other data mining methods. Our work is therefore based on the need to establish a flexible, transparent, consistent straightforward, simple to understand and easy to implement approach. This is achieved
Data mining with WEKA Part 3 Nearest Neighbor and IBM
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
Automated web usage data mining and recommendation system
Data mining can be used to turn seemingly meaningless data into useful information, with rules, trends, and inferences that can be used to improve your business and revenue. This article will go over the last common data mining technique, ‘Nearest Neighbor,’ and will show you how to use the WEKA Java library in your server-side code to
Effective Outlier Detection using K-Nearest Neighbor Data
Discretisation of Data in a Binary Neural k-Nearest
The k-nearest neighbor ( k-NN) method is one of the data mining techniques considered to be among the top 10 techniques for data mining [237]. The k-NN method uses the well-known principle of Cicero
A Review of classification in Web Usage Mining using K
What is k-Nearest Neighbors. The model for kNN is the entire training dataset. When a prediction is required for a unseen data instance, the kNN algorithm will search through the training dataset for the k-most similar instances.
IRJET- Classification of Chemical Medicine or Drug using K
Big Data Classification using Fuzzy K-Nearest Neighbor
K Nearest Neighbors Classification – Data Mining Map
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
K Nearest Neighbors Classification – Data Mining Map
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
k‐Nearest Neighbor Algorithm Discovering Knowledge in
What is K-Nearest Neighbor Classification IGI Global
neighbour as an imputation method for treating missing values; Section 6 describes how the Machine Learning algorithms C4.5 and CN2 treat missing data internally; Section 7 performs a comparative study of the k -nearest neighbour algorithm as an imputation
A Review of classification in Web Usage Mining using K
k nearest neighbor (kNN) is an effective and powerful lazy learning algorithm, notwithstanding its easy-to-implement. However, its performance heavily relies on the quality of training data.
Discretisation of Data in a Binary Neural k-Nearest
(PDF) Application of k-Nearest Neighbour Classification in
To summarize, in a k-nearest neighbor method, the outcome Y of the query point X is taken to be the average of the outcomes of its k-nearest neighbors. Technical Details STATISTICA k-Nearest Neighbors (KNN) is a memory-based model defined by a set of objects known as examples (also known as instances) for which the outcome are known (i.e., the examples are labeled).
K-Nearest Neighbor Human-Oriented
MODEL ALGORITMA K-NEAREST NEIGHBOR (K-NN) PDF Free
To summarize, in a k-nearest neighbor method, the outcome Y of the query point X is taken to be the average of the outcomes of its k-nearest neighbors. Technical Details STATISTICA k-Nearest Neighbors (KNN) is a memory-based model defined by a set of objects known as examples (also known as instances) for which the outcome are known (i.e., the examples are labeled).
Algorithmic Incompleteness of k-Nearest Neighbour in
What is K-Nearest Neighbor Classification IGI Global
Nearest neighbor is a special case of k-nearest neighbor class. Where k value is 1 (k = 1). In this case, new data point target class will be assigned to the 1 Where k value is 1 (k = 1). In this case, new data point target class will be assigned to the 1 st closest neighbor.
A Review on Recommendation System and Web Usage Data
54 Responses to K-Nearest Neighbors for Machine Learning Roberto July 23, 2016 at 4:37 am # KNN is good to looking for nearest date in two sets of data, excluding the nearest neighbor used? if not, what algorithm you should suggest me to solve the issue.
A data mining approach for fall detection by using k
pattern recognition, information retrieval, machine learning, and data mining. Cluster analysis is Cluster analysis is a challenging task and there are a number of well …
IRJET- Classification of Chemical Medicine or Drug using K
k‐Nearest Neighbor Algorithm Discovering Knowledge in
K-Nearest Neighbor Human-Oriented
What is k-Nearest Neighbors. The model for kNN is the entire training dataset. When a prediction is required for a unseen data instance, the kNN algorithm will search through the training dataset for the k-most similar instances.
Data Classification Algorithm Using k-Nearest Neighbour
A Review on Recommendation System and Web Usage Data
Integrating k nearest neighbour single Inlier Outlier Range Random Row Random Attribute with k-means clustering could enhance k nearest neighbour accuracy in the diagnosis of heart disease FIGURE 5: INTEGRATING CLUSTERING WITH K NEAREST patients. The best results for the k nearest neighbour NEIGHBOUR is achieved by the two clusters inlier initial centroid selection …
Noisy data elimination using mutual k-nearest neighbor for
Algorithmic Incompleteness of k-Nearest Neighbour in
A MapReduce-Based k-Nearest Neighbor Approach for Big Data
k-Nearest Neighbour, binary neural network, discretisation, binning, quantisation I. INTRODUCTION Standard k-Nearest Neighbour (k-NN) is a widely applicable data mining algorithm that
13. k-Nearest Neighbors Data Algorithms [Book]
A Review of Data Classification Using K-Nearest Neighbour Algorithm Aman Kataria1, M. D. Singh2 1P.G. Scholar, Thapar University, Cover and Hart proposed an algorithm the K-Nearest Neighbor, which was finalized after some time. K-Nearest Neighbor can be calculated by calculating Euclidian distance, although other measures are also available but through Euclidian distance we have splendid
K-Nearest Neighbours GeeksforGeeks
K-Nearest Neighbor (K-NN) Techopedia.com
Data Mining Algorithms In R/Classification/kNN Wikibooks
Find the K nearest neighbors in the training data set based on the Euclidean distance Predict the class value by finding the maximum class represented in the K nearest neighbors Calculate the accuracy as n Accuracy = (# of correctly classified examples / # of testing examples) X 100. Example of Backward Elimination ¨ # training examples 100 ¨ # testing examples 100 ¨ # attributes 50 ¨ K 3
Learning Algorithm Oregon State University
Discretisation of Data in a Binary Neural k-Nearest
A MapReduce-Based k-Nearest Neighbor Approach for Big Data
29/12/2017 · k nearest neighbour algorithm in data mining belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection
k-Nearest Neighbor (kNN) data mining algorithm in plain
A New Shared Nearest Neighbor Clustering Algorithm and its
k-nearest neighbor algorithm Summary The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security.
A data mining approach for fall detection by using k
A k-nearest-neighbor algorithm, often abbreviated k-nn, is an approach to data classification that estimates how likely a data point is to be a member of one group or the other depending on what group the data points nearest to it are in.
KNN SlideShare
What is K-Nearest Neighbor Classification IGI Global
Discretisation of Data in a Binary Neural k-Nearest
Find the K nearest neighbors in the training data set based on the Euclidean distance Predict the class value by finding the maximum class represented in the K nearest neighbors Calculate the accuracy as n Accuracy = (# of correctly classified examples / # of testing examples) X 100. Example of Backward Elimination ¨ # training examples 100 ¨ # testing examples 100 ¨ # attributes 50 ¨ K 3
Application of k-Nearest Neighbour Classification Method
Data mining with WEKA Part 3 Nearest Neighbor and IBM
Automated web usage data mining and recommendation system
k nearest neighbor (kNN) is an effective and powerful lazy learning algorithm, notwithstanding its easy-to-implement. However, its performance heavily relies on the quality of training data.
k Nearest Neighbors algorithm (kNN) Lkozma
29/12/2017 · k nearest neighbour algorithm in data mining belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection
K-Nearest Neighbours GeeksforGeeks
algorithm to improve the classification accuracy of drug data Classification of Heart Disease Using K- Nearest set or medicine. We used to genetic search as better result Neighbor and Genetic Algorithm…
A data mining approach for fall detection by using k
Applying k-Nearest Neighbour in Diagnosing Heart Disease
To summarize, in a k-nearest neighbor method, the outcome Y of the query point X is taken to be the average of the outcomes of its k-nearest neighbors. Technical Details STATISTICA k-Nearest Neighbors (KNN) is a memory-based model defined by a set of objects known as examples (also known as instances) for which the outcome are known (i.e., the examples are labeled).
A Study of K-Nearest Neighbour as an Imputation Method
knn (k nearest neighbor) algorithm in data mining YouTube
KNN SlideShare
A data mining approach for fall detection by using k-nearest neighbor algorithm on wireless sensor network data Article in IET Communications 6(18):3281-3287 · December 2012 with 62 Reads
Noisy data elimination using mutual k-nearest neighbor for
k‐Nearest Neighbor Algorithm Discovering Knowledge in
In this paper we implemented the Fuzzy K-Nearest Neighbor method using the MapReduce paradigm to process on big data. Results on different data sets show that the proposed Fuzzy K-Nearest Neighbor method outperforms a better performance than the method reviewed in the literature.
Big Data Classification using Fuzzy K-Nearest Neighbor
Machine Learning K-Nearest Neighbors (KNN) algorithm
k nearest neighbor (kNN) is an effective and powerful lazy learning algorithm, notwithstanding its easy-to-implement. However, its performance heavily relies on the quality of training data.
A data mining approach for fall detection by using k
ORIGINS OF K-NN • Nearest Neighbors have been used in statistical estimation and pattern recognition already in the beginning of 1970’s (non- parametric techniques). • The method prevailed in several disciplines and still it is one of the top 10 Data Mining algorithm.
Data Classification Algorithm Using k-Nearest Neighbour
Here, the k-Nearest Neighbor Algorithm Pseudo Code is framed using a function kNN() which takes a single test sample or instance, x as argument and returns a 2-D Vector containing the prediction result as the 1st element and the value of k as the 2nd element.
Noisy data elimination using mutual k-nearest neighbor for
Effective Outlier Detection using K-Nearest Neighbor Data
Machine Learning K-Nearest Neighbors (KNN) algorithm
To summarize, in a k-nearest neighbor method, the outcome Y of the query point X is taken to be the average of the outcomes of its k-nearest neighbors. Technical Details STATISTICA k-Nearest Neighbors (KNN) is a memory-based model defined by a set of objects known as examples (also known as instances) for which the outcome are known (i.e., the examples are labeled).
CLUSTERING WITH SHARED NEAREST NEIGHBOR-UNSCENTED
Outline The Classi cation Problem The k Nearest Neighbours Algorithm Condensed Nearest Neighbour Data Reduction Introduction to kNN Classi cation and CNN Data Reduction Oliver Sutton February, 2012 1/29. Outline The Classi cation Problem The k Nearest Neighbours Algorithm Condensed Nearest Neighbour Data Reduction 1 The Classi cation Problem Examples The Problem 2 The k Nearest …
knn (k nearest neighbor) algorithm in data mining YouTube
Learning Algorithm Oregon State University
Discretisation of Data in a Binary Neural k-Nearest
Nearest neighbor search Edo Liberty Algorithms in Data mining 1 Introduction The problem most commonly known as nearest neighbor search” is a fundamen-
Integrating Clustering with Different Data Mining
knn (k nearest neighbor) algorithm in data mining YouTube
k‐Nearest Neighbor Algorithm Discovering Knowledge in
Many data mining techniques like k-Nearest Neighbour (kNN), Association Rule Mining etc., have been applied to intrusion detection. This paper aims at application of kNN to a subset of records from the KDD Cup 1999 dataset for classification of connection records into normal or attacked data. The paper also applies kNN to the subset of records with the selected features proposed by Kok-Chin
Text Classification using K Nearest Neighbors – Towards
The k-nearest neighbor ( k-NN) method is one of the data mining techniques considered to be among the top 10 techniques for data mining [237]. The k-NN method uses the well-known principle of Cicero
KNN SlideShare
K-Nearest Neighbours GeeksforGeeks
k-Nearest Neighbour, binary neural network, discretisation, binning, quantisation I. INTRODUCTION Standard k-Nearest Neighbour (k-NN) is a widely applicable data mining algorithm that
13. k-Nearest Neighbors Data Algorithms [Book]
k Nearest Neighbors algorithm (kNN) Lkozma
In this paper we implemented the Fuzzy K-Nearest Neighbor method using the MapReduce paradigm to process on big data. Results on different data sets show that the proposed Fuzzy K-Nearest Neighbor method outperforms a better performance than the method reviewed in the literature.
k Nearest Neighbors algorithm (kNN) Lkozma
Nearest neighbor is a special case of k-nearest neighbor class. Where k value is 1 (k = 1). In this case, new data point target class will be assigned to the 1 Where k value is 1 (k = 1). In this case, new data point target class will be assigned to the 1 st closest neighbor.
Discretisation of Data in a Binary Neural k-Nearest
Data Classification Algorithm Using k-Nearest Neighbour
also a number of more technical books about data mining algorithms, but these are aimed at the statistical researcher, or more advanced graduate student, and do not provide the case-oriented business focus that is successful in teaching business students.
K Nearest Neighbour Algorithm Data Mining
The kNN data mining algorithm is part of a longer article about many more data mining algorithms. What does it do? kNN, or k-Nearest Neighbors, is a classification algorithm.
Applying k-Nearest Neighbour in Diagnosing Heart Disease
in the diagnosis of heart disease. K-Nearest-Neighbour(KNN) is one of the successful data mining techniques used in classification problems. However, it is less used in the diagnosis of heart disease patients. Recently, researchers are showing that combining different classifiers through voting is outperforming other single classifiers. This paper investigates applying KNN to help healthcare
Noisy data elimination using mutual k-nearest neighbor for
Big Data Classification using Fuzzy K-Nearest Neighbor
easy data mining. k-Nearest Neighbour (kNN) they used bioinformatics resources extensively, although they The k-nearest neighbours algorithm is one of the simplest machine learning algorithms. It is simply based on the idea that “objects that are ‘near’ each other will also have similar characteristics. Thus if you know the characteristic features of one of the objects, you can also
Nearest neighbor search GitHub Pages
classification algorithms in data mining. It is based on homogeneity, which is drawing a comparison between the K Nearest Neighbor classification provide us with the decision outline locally which was developed due to the need to carry out discriminate analysis when reliable parametric estimates of probability densities are unknown or hard to define. K is a constant pre-defined by the user
Data mining with WEKA Part 3 Nearest Neighbor and IBM
K-Nearest Neighbours GeeksforGeeks
Learning Algorithm Oregon State University
Definition of K-Nearest Neighbor Classification: Is a data mining algorithm that is used to classify a given set of data into pre-defined classes. This algorithm is an example of supervised learning. This algorithm is an example of supervised learning.
K-Nearest Neighbor (K-NN) Techopedia.com
K Nearest Neighbour Algorithm Data Mining
K-Nearest Neighbors, or KNN, is a family of simple: classification. and regression algorithms . based on Similarity (Distance) calculation between instances. Nearest Neighbor implements rote learning. It’s based on a local average calculation. It’s a smoother algorithm. Some experts have written that k-nearest neighbours do the best about one third of the time. It’s so simple that, in the game
Data Mining Algorithms In R/Classification/kNN Wikibooks
Applying k-Nearest Neighbour in Diagnosing Heart Disease
pattern recognition, information retrieval, machine learning, and data mining. Cluster analysis is Cluster analysis is a challenging task and there are a number of well …
A Review on Recommendation System and Web Usage Data
Nearest neighbor search GitHub Pages
Journal of Technology Application of k- Nearest Neighbour
K-nearest neighbour algorithm (KNN) is a classification method based on closest training samples. It It is an instance-based learning algorithms that, instead of …
k Nearest Neighbors algorithm (kNN) Lkozma
The K-Nearest Neighbor (K-NN) algorithm is one of the simplest methods for solving classification problems; it often yields competitive results and has significant advantages over several other data mining methods. Our work is therefore based on the need to establish a flexible, transparent, consistent straightforward, simple to understand and easy to implement approach. This is achieved
Big Data Classification using Fuzzy K-Nearest Neighbor
Data Classification Algorithm Using k-Nearest Neighbour
k-nearest neighbor algorithm Summary The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security.
K Nearest Neighbors Classification – Data Mining Map
In this paper we implemented the Fuzzy K-Nearest Neighbor method using the MapReduce paradigm to process on big data. Results on different data sets show that the proposed Fuzzy K-Nearest Neighbor method outperforms a better performance than the method reviewed in the literature.
k‐Nearest Neighbor Algorithm Discovering Knowledge in
(PDF) Application of k-Nearest Neighbour Classification in
The K-Nearest Neighbour algorithm is similar to the Nearest Neighbour algorithm, except that it looks at the closest K instances to the unclassified instance. The class of the new instance is then given by the class with the highest frequency of those K instances.
A New Shared Nearest Neighbor Clustering Algorithm and its
Machine Learning K-Nearest Neighbors (KNN) algorithm
K-Nearest Neighbor Data Distributions. We run experiments on a variety of data stream We run experiments on a variety of data stream topologies and thereby demonstrate the effectiveness of the new algorithm in detecting outliers
Big Data Classification using Fuzzy K-Nearest Neighbor
k‐Nearest Neighbor Algorithm Discovering Knowledge in
k-Nearest Neighbour, binary neural network, discretisation, binning, quantisation I. INTRODUCTION Standard k-Nearest Neighbour (k-NN) is a widely applicable data mining algorithm that
knn (k nearest neighbor) algorithm in data mining YouTube
k-nearest neighbor algorithm Summary The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security.
Text Classification using K Nearest Neighbors – Towards
k Nearest Neighbors algorithm (kNN) Lkozma
Effective Outlier Detection using K-Nearest Neighbor Data
The K-Nearest Neighbor (K-NN) algorithm is one of the simplest methods for solving classification problems; it often yields competitive results and has significant advantages over several other data mining methods. Our work is therefore based on the need to establish a flexible, transparent, consistent straightforward, simple to understand and easy to implement approach. This is achieved
k-Nearest Neighbor Algorithm Discovering Knowledge in
In this paper we implemented the Fuzzy K-Nearest Neighbor method using the MapReduce paradigm to process on big data. Results on different data sets show that the proposed Fuzzy K-Nearest Neighbor method outperforms a better performance than the method reviewed in the literature.
k-Nearest Neighbor Classification SpringerLink
ORIGINS OF K-NN • Nearest Neighbors have been used in statistical estimation and pattern recognition already in the beginning of 1970’s (non- parametric techniques). • The method prevailed in several disciplines and still it is one of the top 10 Data Mining algorithm.
k‐Nearest Neighbor Algorithm Discovering Knowledge in
k-Nearest Neighbor Classification SpringerLink
k nearest neighbor (kNN) is an effective and powerful lazy learning algorithm, notwithstanding its easy-to-implement. However, its performance heavily relies on the quality of training data.
Effective Outlier Detection using K-Nearest Neighbor Data
knn (k nearest neighbor) algorithm in data mining YouTube
Nearest Neighbor Algorithm Store all of the training examples Classify a new example x by finding the training example hx i, y ii that is nearest to x according to
A New Shared Nearest Neighbor Clustering Algorithm and its
Data mining is the process of extracting the data from huge high dimensional databases, used as technology to produce the required information. The tendency of high-dimensional data enclose points hubs as shown in [1] that frequently occur in k-nearest neighbor lists of other points. Hubness successfully subjugated in clustering within a high-dimensional data cluster. Hub objects have minute
A Study of K-Nearest Neighbour as an Imputation Method
Data mining can be used to turn seemingly meaningless data into useful information, with rules, trends, and inferences that can be used to improve your business and revenue. This article will go over the last common data mining technique, ‘Nearest Neighbor,’ and will show you how to use the WEKA Java library in your server-side code to
MODEL ALGORITMA K-NEAREST NEIGHBOR (K-NN) PDF Free
29/12/2017 · k nearest neighbour algorithm in data mining belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection
K-Nearest Neighbor (K-NN) Techopedia.com
Select a cell on the Data_Partition worksheet, then on the XLMiner ribbon, from the Data Mining tab, select Classify – k-Nearest Neighbors Classification to open the k-Nearest Neighbors Classification – Step 1 of 3 dialog.
Learning Algorithm Oregon State University
knn (k nearest neighbor) algorithm in data mining YouTube
A Study of K-Nearest Neighbour as an Imputation Method
54 Responses to K-Nearest Neighbors for Machine Learning Roberto July 23, 2016 at 4:37 am # KNN is good to looking for nearest date in two sets of data, excluding the nearest neighbor used? if not, what algorithm you should suggest me to solve the issue.
k-Nearest Neighbor Algorithm Discovering Knowledge in
KNN SlideShare
K-Nearest Neighbor Human-Oriented
Definition of K-Nearest Neighbor Classification: Is a data mining algorithm that is used to classify a given set of data into pre-defined classes. This algorithm is an example of supervised learning. This algorithm is an example of supervised learning.
k-Nearest Neighbor Algorithm Discovering Knowledge in
Applying k-Nearest Neighbour in Diagnosing Heart Disease
The kNN data mining algorithm is part of a longer article about many more data mining algorithms. What does it do? kNN, or k-Nearest Neighbors, is a classification algorithm.
A data mining approach for fall detection by using k
MODEL ALGORITMA K-NEAREST NEIGHBOR (K-NN) PDF Free
A Review of classification in Web Usage Mining using K
in the diagnosis of heart disease. K-Nearest-Neighbour(KNN) is one of the successful data mining techniques used in classification problems. However, it is less used in the diagnosis of heart disease patients. Recently, researchers are showing that combining different classifiers through voting is outperforming other single classifiers. This paper investigates applying KNN to help healthcare
CLUSTERING WITH SHARED NEAREST NEIGHBOR-UNSCENTED
Algorithmic Incompleteness of k-Nearest Neighbour in
k-Nearest Neighbour, binary neural network, discretisation, binning, quantisation I. INTRODUCTION Standard k-Nearest Neighbour (k-NN) is a widely applicable data mining algorithm that
k-Nearest Neighbor (kNN) data mining algorithm in plain
k Nearest Neighbors algorithm (kNN) Lkozma
The K-Nearest Neighbour algorithm is similar to the Nearest Neighbour algorithm, except that it looks at the closest K instances to the unclassified instance. The class of the new instance is then given by the class with the highest frequency of those K instances.
k-Nearest Neighbor Algorithm Discovering Knowledge in
Nearest neighbor search GitHub Pages
To summarize, in a k-nearest neighbor method, the outcome Y of the query point X is taken to be the average of the outcomes of its k-nearest neighbors. Technical Details STATISTICA k-Nearest Neighbors (KNN) is a memory-based model defined by a set of objects known as examples (also known as instances) for which the outcome are known (i.e., the examples are labeled).
CLUSTERING WITH SHARED NEAREST NEIGHBOR-UNSCENTED
K Nearest Neighbors Classification – Data Mining Map
k-Nearest Neighbour, binary neural network, discretisation, binning, quantisation I. INTRODUCTION Standard k-Nearest Neighbour (k-NN) is a widely applicable data mining algorithm that
k-Nearest Neighbors Classification Method Example solver
knn (k nearest neighbor) algorithm in data mining YouTube
Journal of Technology Application of k- Nearest Neighbour
K-Nearest Neighbor. Definition K-Nearest neighbor is a classification strategy that is an example of a “lazy learner.” Unlike all the other classification algorithms outlined on this site which are labeled “eager learners” “lazy learners” do not require building a model with a training set before actual use.
CLUSTERING WITH SHARED NEAREST NEIGHBOR-UNSCENTED
K-Nearest Neighbors is one of the most basic yet essential classification algorithms in Machine Learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection. It is widely disposable in real-life scenarios since it is
CLUSTERING WITH SHARED NEAREST NEIGHBOR-UNSCENTED
A Study of K-Nearest Neighbour as an Imputation Method
K-Nearest Neighbours GeeksforGeeks
Select a cell on the Data_Partition worksheet, then on the XLMiner ribbon, from the Data Mining tab, select Classify – k-Nearest Neighbors Classification to open the k-Nearest Neighbors Classification – Step 1 of 3 dialog.
Applying k-Nearest Neighbour in Diagnosing Heart Disease
Nearest neighbor search Edo Liberty Algorithms in Data mining 1 Introduction The problem most commonly known as nearest neighbor search” is a fundamen-
k Nearest Neighbors algorithm (kNN) Lkozma
also a number of more technical books about data mining algorithms, but these are aimed at the statistical researcher, or more advanced graduate student, and do not provide the case-oriented business focus that is successful in teaching business students.
Journal of Technology Application of k- Nearest Neighbour
k nearest neighbor (kNN) is an effective and powerful lazy learning algorithm, notwithstanding its easy-to-implement. However, its performance heavily relies on the quality of training data.
Integrating Clustering with Different Data Mining
Noisy data elimination using mutual k-nearest neighbor for
k-Nearest Neighbors Classification Method Example solver
K-nearest neighbour algorithm (KNN) is a classification method based on closest training samples. It It is an instance-based learning algorithms that, instead of …
IRJET- Classification of Chemical Medicine or Drug using K
A Study of K-Nearest Neighbour as an Imputation Method
The K-Nearest Neighbor (K-NN) algorithm is one of the simplest methods for solving classification problems; it often yields competitive results and has significant advantages over several other data mining methods. Our work is therefore based on the need to establish a flexible, transparent, consistent straightforward, simple to understand and easy to implement approach. This is achieved
A data mining approach for fall detection by using k
Noisy data elimination using mutual k-nearest neighbor for
Find the K nearest neighbors in the training data set based on the Euclidean distance Predict the class value by finding the maximum class represented in the K nearest neighbors Calculate the accuracy as n Accuracy = (# of correctly classified examples / # of testing examples) X 100. Example of Backward Elimination ¨ # training examples 100 ¨ # testing examples 100 ¨ # attributes 50 ¨ K 3
(PDF) Application of k-Nearest Neighbour Classification in
Application of k-Nearest Neighbour Classification Method
MODEL ALGORITMA K-NEAREST NEIGHBOR (K-NN) PDF Free
easy data mining. k-Nearest Neighbour (kNN) they used bioinformatics resources extensively, although they The k-nearest neighbours algorithm is one of the simplest machine learning algorithms. It is simply based on the idea that “objects that are ‘near’ each other will also have similar characteristics. Thus if you know the characteristic features of one of the objects, you can also
Applying k-Nearest Neighbour in Diagnosing Heart Disease
k nearest neighbor (kNN) is an effective and powerful lazy learning algorithm, notwithstanding its easy-to-implement. However, its performance heavily relies on the quality of training data.
Effective Outlier Detection using K-Nearest Neighbor Data
k-Nearest Neighbor Classification SpringerLink
K-Nearest Neighbor (K-NN) Techopedia.com
K-nearest neighbour algorithm (KNN) is a classification method based on closest training samples. It It is an instance-based learning algorithms that, instead of …
Automated web usage data mining and recommendation system
k‐Nearest Neighbor Algorithm Discovering Knowledge in
The “K” is KNN algorithm is the nearest neighbors we wish to take vote from. Let’s say K = 3. Hence, we will now make a circle with BS as center just as big as to enclose only three datapoints on the plane. Refer to following diagram for more details:
K Nearest Neighbors Classification – Data Mining Map
Machine Learning K-Nearest Neighbors (KNN) algorithm
The K-Nearest Neighbour algorithm is similar to the Nearest Neighbour algorithm, except that it looks at the closest K instances to the unclassified instance. The class of the new instance is then given by the class with the highest frequency of those K instances.
MODEL ALGORITMA K-NEAREST NEIGHBOR (K-NN) PDF Free
k‐Nearest Neighbor Algorithm Discovering Knowledge in
Find the K nearest neighbors in the training data set based on the Euclidean distance Predict the class value by finding the maximum class represented in the K nearest neighbors Calculate the accuracy as n Accuracy = (# of correctly classified examples / # of testing examples) X 100. Example of Backward Elimination ¨ # training examples 100 ¨ # testing examples 100 ¨ # attributes 50 ¨ K 3
A New Shared Nearest Neighbor Clustering Algorithm and its
Applying k-Nearest Neighbour in Diagnosing Heart Disease
prediction. k-Nearest neighbor is an example of instance-based learning, in which the training data set is stored, so that a classification for a new unclassified record may be found simply by comparing it to the most similar records in the training set.
Data Mining Algorithms In R/Classification/kNN Wikibooks
Abstract— Classification is a data mining (machine learning) technique used to predict group membership for data instances. In this paper, we present the basic classification techniques. Several major kinds of classification method including decision tree induction, Bayesian networks, k-nearest neighbor classifier, case-based reasoning, genetic algorithm and fuzzy logic techniques. The goal
(PDF) Application of k-Nearest Neighbour Classification in
A Review of Data Classification Using K-Nearest Neighbour
K-Nearest Neighbor Human-Oriented
The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security. The author investigates k‐nearest neighbor algorithm, which is most often used for classification task, although it can
A Review of Data Classification Using K-Nearest Neighbour
A Review on Recommendation System and Web Usage Data
Outline The Classi cation Problem The k Nearest Neighbours Algorithm Condensed Nearest Neighbour Data Reduction Introduction to kNN Classi cation and CNN Data Reduction Oliver Sutton February, 2012 1/29. Outline The Classi cation Problem The k Nearest Neighbours Algorithm Condensed Nearest Neighbour Data Reduction 1 The Classi cation Problem Examples The Problem 2 The k Nearest …
Applying k-Nearest Neighbour in Diagnosing Heart Disease
What is K-Nearest Neighbor Classification IGI Global
Abstract— Classification is a data mining (machine learning) technique used to predict group membership for data instances. In this paper, we present the basic classification techniques. Several major kinds of classification method including decision tree induction, Bayesian networks, k-nearest neighbor classifier, case-based reasoning, genetic algorithm and fuzzy logic techniques. The goal
Big Data Classification using Fuzzy K-Nearest Neighbor
A New Shared Nearest Neighbor Clustering Algorithm and its
Nearest Neighbor Algorithm Store all of the training examples Classify a new example x by finding the training example hx i, y ii that is nearest to x according to
k Nearest Neighbors algorithm (kNN) Lkozma
K Nearest Neighbors Classification – Data Mining Map
k nearest neighbor (kNN) is an effective and powerful lazy learning algorithm, notwithstanding its easy-to-implement. However, its performance heavily relies on the quality of training data.
Integrating Clustering with Different Data Mining
What is K-Nearest Neighbor Classification IGI Global
Big Data Classification using Fuzzy K-Nearest Neighbor
k-Nearest Neighbor Algorithm for Classification K. Ming Leung Abstract: An instance based learning method called the K-Nearest Neighbor or K-NN algorithm has been used in many applications in areas such as data mining, statistical pattern recognition, image processing. Suc-cessful applications include recognition of handwriting, satellite image and EKG pattern. Directory • Table of Contents
Big Data Classification using Fuzzy K-Nearest Neighbor
Data Classification Algorithm Using k-Nearest Neighbour
Data mining with WEKA Part 3 Nearest Neighbor and IBM
Data mining is the process of extracting the data from huge high dimensional databases, used as technology to produce the required information. The tendency of high-dimensional data enclose points hubs as shown in [1] that frequently occur in k-nearest neighbor lists of other points. Hubness successfully subjugated in clustering within a high-dimensional data cluster. Hub objects have minute
K-Nearest Neighbor Human-Oriented
Teknik K-Nearest Neighbor dengan melakukan langkah-langkah yaitu (Santoso, 2007), mulai input: Data training, label data traning, k, data testing a. Untuk semua data testing, hitung jaraknya ke setiap data training b. Tentukan k data training yang jaraknya paling dekat dengan data c. Testing d. Periksa label dari k data ini e. Tentukan label yang frekuensinya paling banyak f. Masukan data
K Nearest Neighbors Classification – Data Mining Map
Integrating Clustering with Different Data Mining
CLUSTERING WITH SHARED NEAREST NEIGHBOR-UNSCENTED
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
k-Nearest Neighbor Algorithm Discovering Knowledge in
The K-Nearest Neighbor (K-NN) algorithm is one of the simplest methods for solving classification problems; it often yields competitive results and has significant advantages over several other data mining methods. Our work is therefore based on the need to establish a flexible, transparent, consistent straightforward, simple to understand and easy to implement approach. This is achieved
(PDF) Application of k-Nearest Neighbour Classification in
Application of k-Nearest Neighbour Classification Method
K-Nearest Neighbors, or KNN, is a family of simple: classification. and regression algorithms . based on Similarity (Distance) calculation between instances. Nearest Neighbor implements rote learning. It’s based on a local average calculation. It’s a smoother algorithm. Some experts have written that k-nearest neighbours do the best about one third of the time. It’s so simple that, in the game
K-Nearest Neighbor Human-Oriented
easy data mining. k-Nearest Neighbour (kNN) they used bioinformatics resources extensively, although they The k-nearest neighbours algorithm is one of the simplest machine learning algorithms. It is simply based on the idea that “objects that are ‘near’ each other will also have similar characteristics. Thus if you know the characteristic features of one of the objects, you can also
K-Nearest Neighbours GeeksforGeeks
A Review of Data Classification Using K-Nearest Neighbour
K-Nearest Neighbor Human-Oriented
ORIGINS OF K-NN • Nearest Neighbors have been used in statistical estimation and pattern recognition already in the beginning of 1970’s (non- parametric techniques). • The method prevailed in several disciplines and still it is one of the top 10 Data Mining algorithm.
Discretisation of Data in a Binary Neural k-Nearest
Application of k-Nearest Neighbour Classification Method
MODEL ALGORITMA K-NEAREST NEIGHBOR (K-NN) PDF Free
The kNN data mining algorithm is part of a longer article about many more data mining algorithms. What does it do? kNN, or k-Nearest Neighbors, is a classification algorithm.
Data Mining Algorithms In R/Classification/kNN Wikibooks
A New Shared Nearest Neighbor Clustering Algorithm and its
k-Nearest Neighbor (kNN) data mining algorithm in plain
To summarize, in a k-nearest neighbor method, the outcome Y of the query point X is taken to be the average of the outcomes of its k-nearest neighbors. Technical Details STATISTICA k-Nearest Neighbors (KNN) is a memory-based model defined by a set of objects known as examples (also known as instances) for which the outcome are known (i.e., the examples are labeled).
A data mining approach for fall detection by using k
The kNN data mining algorithm is part of a longer article about many more data mining algorithms. What does it do? kNN, or k-Nearest Neighbors, is a classification algorithm.
CLUSTERING WITH SHARED NEAREST NEIGHBOR-UNSCENTED
A Review of classification in Web Usage Mining using K
(PDF) Application of k-Nearest Neighbour Classification in
K-nearest neighbour algorithm (KNN) is a classification method based on closest training samples. It It is an instance-based learning algorithms that, instead of …
A MapReduce-Based k-Nearest Neighbor Approach for Big Data
Big Data Classification using Fuzzy K-Nearest Neighbor
k-nearest neighbor algorithm Summary The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security.
k-Nearest Neighbor Classification SpringerLink
Teknik K-Nearest Neighbor dengan melakukan langkah-langkah yaitu (Santoso, 2007), mulai input: Data training, label data traning, k, data testing a. Untuk semua data testing, hitung jaraknya ke setiap data training b. Tentukan k data training yang jaraknya paling dekat dengan data c. Testing d. Periksa label dari k data ini e. Tentukan label yang frekuensinya paling banyak f. Masukan data
K-Nearest Neighbor Human-Oriented
13. k-Nearest Neighbors Data Algorithms [Book]
The KNN or k-nearest neighbors algorithm is one of the simplest machine learning algorithms and is an example of instance-based learning, where new data are classified based on …
K-Nearest Neighbor Human-Oriented
Noisy data elimination using mutual k-nearest neighbor for
k-Nearest Neighbor Algorithm Discovering Knowledge in
Here, the k-Nearest Neighbor Algorithm Pseudo Code is framed using a function kNN() which takes a single test sample or instance, x as argument and returns a 2-D Vector containing the prediction result as the 1st element and the value of k as the 2nd element.
Application of k-Nearest Neighbour Classification Method
A New Shared Nearest Neighbor Clustering Algorithm and its
knn (k nearest neighbor) algorithm in data mining YouTube
prediction. k-Nearest neighbor is an example of instance-based learning, in which the training data set is stored, so that a classification for a new unclassified record may be found simply by comparing it to the most similar records in the training set.
Learning Algorithm Oregon State University
K Nearest Neighbors Classification – Data Mining Map
in the diagnosis of heart disease. K-Nearest-Neighbour(KNN) is one of the successful data mining techniques used in classification problems. However, it is less used in the diagnosis of heart disease patients. Recently, researchers are showing that combining different classifiers through voting is outperforming other single classifiers. This paper investigates applying KNN to help healthcare
Data Classification Algorithm Using k-Nearest Neighbour
k-Nearest Neighbor Classification SpringerLink
Automated web usage data mining and recommendation system
Nearest neighbor is a special case of k-nearest neighbor class. Where k value is 1 (k = 1). In this case, new data point target class will be assigned to the 1 Where k value is 1 (k = 1). In this case, new data point target class will be assigned to the 1 st closest neighbor.
MODEL ALGORITMA K-NEAREST NEIGHBOR (K-NN) PDF Free
K Nearest Neighbors Classification – Data Mining Map
A MapReduce-Based k-Nearest Neighbor Approach for Big Data
People in data mining never test with the data they used to train the system. You can see why we don’t use the training data for testing if we consider the nearest neighbor algorithm.
(PDF) Application of k-Nearest Neighbour Classification in
K-Nearest Neighbor (K-NN) Techopedia.com
A New Shared Nearest Neighbor Clustering Algorithm and its
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
Automated web usage data mining and recommendation system
MODEL ALGORITMA K-NEAREST NEIGHBOR (K-NN) PDF Free
Data Classification Algorithm Using k-Nearest Neighbour
People in data mining never test with the data they used to train the system. You can see why we don’t use the training data for testing if we consider the nearest neighbor algorithm.
CLUSTERING WITH SHARED NEAREST NEIGHBOR-UNSCENTED
A New Shared Nearest Neighbor Clustering Algorithm and its
Definition of K-Nearest Neighbor Classification: Is a data mining algorithm that is used to classify a given set of data into pre-defined classes. This algorithm is an example of supervised learning. This algorithm is an example of supervised learning.
A MapReduce-Based k-Nearest Neighbor Approach for Big Data
K-Nearest Neighbor (K-NN) Techopedia.com
Algorithmic Incompleteness of k-Nearest Neighbour in
Teknik K-Nearest Neighbor dengan melakukan langkah-langkah yaitu (Santoso, 2007), mulai input: Data training, label data traning, k, data testing a. Untuk semua data testing, hitung jaraknya ke setiap data training b. Tentukan k data training yang jaraknya paling dekat dengan data c. Testing d. Periksa label dari k data ini e. Tentukan label yang frekuensinya paling banyak f. Masukan data
A MapReduce-Based k-Nearest Neighbor Approach for Big Data
People in data mining never test with the data they used to train the system. You can see why we don’t use the training data for testing if we consider the nearest neighbor algorithm.
K-Nearest Neighbours GeeksforGeeks
K-Nearest Neighbor Human-Oriented
Definition of K-Nearest Neighbor Classification: Is a data mining algorithm that is used to classify a given set of data into pre-defined classes. This algorithm is an example of supervised learning. This algorithm is an example of supervised learning.
13. k-Nearest Neighbors Data Algorithms [Book]
Text Classification using K Nearest Neighbors – Towards
In this paper we implemented the Fuzzy K-Nearest Neighbor method using the MapReduce paradigm to process on big data. Results on different data sets show that the proposed Fuzzy K-Nearest Neighbor method outperforms a better performance than the method reviewed in the literature.
Discretisation of Data in a Binary Neural k-Nearest
A data mining approach for fall detection by using k
easy data mining. k-Nearest Neighbour (kNN) they used bioinformatics resources extensively, although they The k-nearest neighbours algorithm is one of the simplest machine learning algorithms. It is simply based on the idea that “objects that are ‘near’ each other will also have similar characteristics. Thus if you know the characteristic features of one of the objects, you can also
A Review of classification in Web Usage Mining using K
29/12/2017 · k nearest neighbour algorithm in data mining belongs to the supervised learning domain and finds intense application in pattern recognition, data mining and intrusion detection
knn (k nearest neighbor) algorithm in data mining YouTube
Learning Algorithm Oregon State University
A data mining approach for fall detection by using k-nearest neighbor algorithm on wireless sensor network data Article in IET Communications 6(18):3281-3287 · December 2012 with 62 Reads
A Review on Recommendation System and Web Usage Data
Data mining with WEKA Part 3 Nearest Neighbor and IBM
Data mining can be used to turn seemingly meaningless data into useful information, with rules, trends, and inferences that can be used to improve your business and revenue. This article will go over the last common data mining technique, ‘Nearest Neighbor,’ and will show you how to use the WEKA Java library in your server-side code to
What is K-Nearest Neighbor Classification IGI Global
KNN SlideShare
13. k-Nearest Neighbors Data Algorithms [Book]
Data mining techniques have been widely used to mine knowledgeable information from medical data bases. In data mining classification is a supervised learning that can be used to design models describing important data classes, where class attribute is involved in the construction of the classifier. Nearest neighbor (KNN) is very simple, most popular, highly efficient and effective algorithm
Discretisation of Data in a Binary Neural k-Nearest
k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as …
K Nearest Neighbors Classification – Data Mining Map
What is K-Nearest Neighbor Classification IGI Global
Data Mining Algorithms In R/Classification/kNN Wikibooks
The kNN data mining algorithm is part of a longer article about many more data mining algorithms. What does it do? kNN, or k-Nearest Neighbors, is a classification algorithm.
k-Nearest Neighbor (kNN) data mining algorithm in plain
Data Mining Algorithms In R/Classification/kNN Wikibooks
K Nearest Neighbour Algorithm Data Mining
Application of k- Nearest Neighbour Classif ication in Medical Data Mining Hassan Shee Khamis, Kipruto W. Cheruiyot, Steph en Kimani Jomo Kenyatta University of Technology – ICSIT, Nairobi, Kenya.
k Nearest Neighbors algorithm (kNN) Lkozma
In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the k …
What is K-Nearest Neighbor Classification IGI Global
IRJET- Classification of Chemical Medicine or Drug using K
13. k-Nearest Neighbors Data Algorithms [Book]
The KNN or k-nearest neighbors algorithm is one of the simplest machine learning algorithms and is an example of instance-based learning, where new data are classified based on …
KNN SlideShare
Data Mining Algorithms In R/Classification/kNN Wikibooks
K-Nearest Neighbor. Definition K-Nearest neighbor is a classification strategy that is an example of a “lazy learner.” Unlike all the other classification algorithms outlined on this site which are labeled “eager learners” “lazy learners” do not require building a model with a training set before actual use.
IRJET- Classification of Chemical Medicine or Drug using K
k-Nearest Neighbors Classification Method Example solver
neighbour as an imputation method for treating missing values; Section 6 describes how the Machine Learning algorithms C4.5 and CN2 treat missing data internally; Section 7 performs a comparative study of the k -nearest neighbour algorithm as an imputation
K-Nearest Neighbours GeeksforGeeks
Text Classification using K Nearest Neighbors – Towards
in the diagnosis of heart disease. K-Nearest-Neighbour(KNN) is one of the successful data mining techniques used in classification problems. However, it is less used in the diagnosis of heart disease patients. Recently, researchers are showing that combining different classifiers through voting is outperforming other single classifiers. This paper investigates applying KNN to help healthcare
k-Nearest Neighbor (kNN) data mining algorithm in plain
A data mining approach for fall detection by using k
K Nearest Neighbour Algorithm Data Mining
Data mining is the process of extracting the data from huge high dimensional databases, used as technology to produce the required information. The tendency of high-dimensional data enclose points hubs as shown in [1] that frequently occur in k-nearest neighbor lists of other points. Hubness successfully subjugated in clustering within a high-dimensional data cluster. Hub objects have minute
A Review of Data Classification Using K-Nearest Neighbour
also a number of more technical books about data mining algorithms, but these are aimed at the statistical researcher, or more advanced graduate student, and do not provide the case-oriented business focus that is successful in teaching business students.
k-Nearest Neighbor (kNN) data mining algorithm in plain
What is K-Nearest Neighbor Classification IGI Global
Applying k-Nearest Neighbour in Diagnosing Heart Disease
A Review of Data Classification Using K-Nearest Neighbour Algorithm Aman Kataria1, M. D. Singh2 1P.G. Scholar, Thapar University, Cover and Hart proposed an algorithm the K-Nearest Neighbor, which was finalized after some time. K-Nearest Neighbor can be calculated by calculating Euclidian distance, although other measures are also available but through Euclidian distance we have splendid
k-Nearest Neighbors Classification Method Example solver
(PDF) Application of k-Nearest Neighbour Classification in
Algorithmic Incompleteness of k-Nearest Neighbour in
In this paper we implemented the Fuzzy K-Nearest Neighbor method using the MapReduce paradigm to process on big data. Results on different data sets show that the proposed Fuzzy K-Nearest Neighbor method outperforms a better performance than the method reviewed in the literature.
Journal of Technology Application of k- Nearest Neighbour
A MapReduce-Based k-Nearest Neighbor Approach for Big Data
The K-Nearest Neighbor (K-NN) algorithm is one of the simplest methods for solving classification problems; it often yields competitive results and has significant advantages over several other data mining methods. Our work is therefore based on the need to establish a flexible, transparent, consistent straightforward, simple to understand and easy to implement approach. This is achieved
K-Nearest Neighbor Human-Oriented
k Nearest Neighbors algorithm (kNN) Lkozma
Data mining with WEKA Part 3 Nearest Neighbor and IBM
K-Nearest Neighbor. Definition K-Nearest neighbor is a classification strategy that is an example of a “lazy learner.” Unlike all the other classification algorithms outlined on this site which are labeled “eager learners” “lazy learners” do not require building a model with a training set before actual use.
IRJET- Classification of Chemical Medicine or Drug using K
in the diagnosis of heart disease. K-Nearest-Neighbour(KNN) is one of the successful data mining techniques used in classification problems. However, it is less used in the diagnosis of heart disease patients. Recently, researchers are showing that combining different classifiers through voting is outperforming other single classifiers. This paper investigates applying KNN to help healthcare
K-Nearest Neighbours GeeksforGeeks
KNN SlideShare
Nearest neighbor search Edo Liberty Algorithms in Data mining 1 Introduction The problem most commonly known as nearest neighbor search” is a fundamen-
Journal of Technology Application of k- Nearest Neighbour
The k-nearest neighbor ( k-NN) method is one of the data mining techniques considered to be among the top 10 techniques for data mining [237]. The k-NN method uses the well-known principle of Cicero
A MapReduce-Based k-Nearest Neighbor Approach for Big Data
The k-Nearest Neighbor algorithm (k-NN) [2] is considered one of the ten most influential data mining algorithms [3]. It belongs to the lazy learning family of methods that do not need of an explicit training phase. This method requires that all of the data instances are stored and unseen cases classified by finding the class labels of the kclosest instances to them. To determine how close
knn (k nearest neighbor) algorithm in data mining YouTube
A data mining approach for fall detection by using k
A New Shared Nearest Neighbor Clustering Algorithm and its
Nearest neighbor search Edo Liberty Algorithms in Data mining 1 Introduction The problem most commonly known as nearest neighbor search” is a fundamen-
A Review of classification in Web Usage Mining using K
Integrating Clustering with Different Data Mining
The KNN or k-nearest neighbors algorithm is one of the simplest machine learning algorithms and is an example of instance-based learning, where new data are classified based on …
Nearest neighbor search GitHub Pages
prediction. k-Nearest neighbor is an example of instance-based learning, in which the training data set is stored, so that a classification for a new unclassified record may be found simply by comparing it to the most similar records in the training set.
A Review on Recommendation System and Web Usage Data
The most common data mining task is that of classification tasks that may be found in nearly every field of endeavor: banking, education, medicine, law and homeland security. The author investigates k‐nearest neighbor algorithm, which is most often used for classification task, although it can
K-Nearest Neighbor Human-Oriented
A Study of K-Nearest Neighbour as an Imputation Method
K-Nearest Neighbor Data Distributions. We run experiments on a variety of data stream We run experiments on a variety of data stream topologies and thereby demonstrate the effectiveness of the new algorithm in detecting outliers
13. k-Nearest Neighbors Data Algorithms [Book]
A data mining approach for fall detection by using k
54 Responses to K-Nearest Neighbors for Machine Learning Roberto July 23, 2016 at 4:37 am # KNN is good to looking for nearest date in two sets of data, excluding the nearest neighbor used? if not, what algorithm you should suggest me to solve the issue.
Integrating Clustering with Different Data Mining
k-Nearest Neighbor Algorithm for Classification K. Ming Leung Abstract: An instance based learning method called the K-Nearest Neighbor or K-NN algorithm has been used in many applications in areas such as data mining, statistical pattern recognition, image processing. Suc-cessful applications include recognition of handwriting, satellite image and EKG pattern. Directory • Table of Contents
Machine Learning K-Nearest Neighbors (KNN) algorithm